ElevenLabs Voice Settings Guide: How to Get Perfect AI Voices Every Time
If your ElevenLabs AI voice sounds robotic, flat, or inconsistent, the problem usually isn’t the tool, it’s the settings.
ElevenLabs offers some of the most realistic text-to-speech voices available today, but without understanding its core controls, you will never unlock its full potential. This guide explains every major ElevenLabs setting in simple terms and shows you exactly how to tune them for YouTube videos, audiobooks, TikTok, AI characters, and emotional storytelling.
By the end, you will know how to make your AI voices sound natural, expressive, and professional at every time.
1. What Is ElevenLabs?
ElevenLabs is an AI powered text to speech and voice cloning platform known for producing ultra-realistic human voices. It’s widely used for:
- YouTube voiceovers
- Audiobooks and narration
- TikTok and short-form content
- AI characters and storytelling
- Dubbing and multilingual content
- Podcasts and educational content
What sets ElevenLabs apart is not just voice quality — it’s the control you get over how the voice sounds.
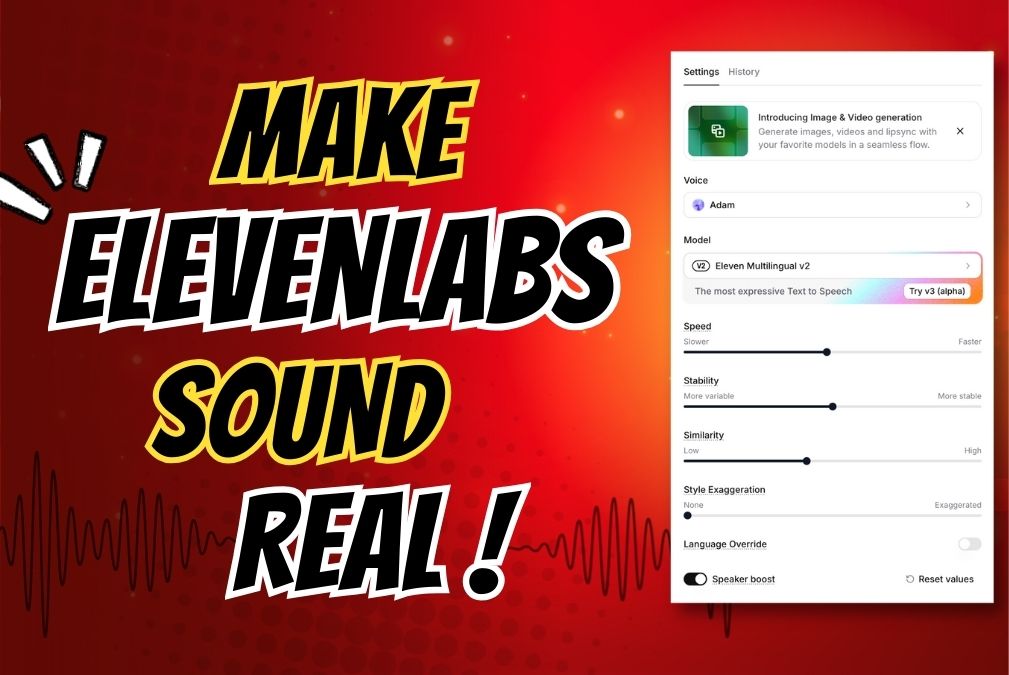
2. Core ElevenLabs Voice Settings Explained
Let’s break down each setting and what it does. This includs practical tips, examples, and common pitfalls, so you can fine tune voices like a pro.
2.1 Speed
What it controls:
Speed adjusts how fast the AI reads your text.
How it affects your audio:
- Slower speed: Produces calm, emotional, or dramatic delivery. Perfect for creating suspense, storytelling, or long-form narration.
- Medium speed: Balanced pacing for tutorials, YouTube narration, or explainer videos. This keeps the listener engaged without feeling rushed.
- Faster speed: Energetic and punchy, suitable for TikTok/Reels, short ads, or instructional content that needs urgency.
Tips for using Speed:
- If your script has complex sentences, slightly slower speed improves clarity.
- Short, casual sentences can handle higher speeds without sounding unnatural.
- Avoid maxing out speed; too fast can make speech robotic or hard to follow.
Example:
- Slow: “Once upon a time, in a quiet village, there lived a mysterious storyteller…”
- Fast: “Quick tip: You can save hours every week with this simple AI hack!”
2.2 Stability
What it controls:
Stability determines how consistent and predictable the voice is. It affects pitch, tone, and emotional fluctuations.
How it affects your audio:
- High stability: Smooth, steady, professional tone. Ideal for corporate narration, news, educational content, or any long video requiring consistency.
- Low stability: Expressive, dynamic, and slightly unpredictable, which is great for storytelling, characters, drama, or emotional scripts.
Tips for using Stability:
- Low stability is excellent for character differentiation. E.g: giving multiple voices distinct personalities.
- For long-form content, higher stability reduces listener fatigue.
- If your goal is emotional impact, experiment with mid-to-low stability combined with style exaggeration.
Think of it like this:
- High stability = News anchor
- Low stability = Actor performing a scene
Example:
- High: Calm, even narration of a tutorial
- Low: Dramatic reading of a suspense story or fantasy character dialogue
2.3 Similarity (Clarity + Similarity Enhancement)
What it controls:
Similarity affects how closely the AI voice matches the original or cloned voice.
How it affects your audio:
- High similarity: Very close to the original voice, useful for branded or cloned voices. Less room for expressive variations.
- Medium similarity: Balanced natural tone with some flexibility — keeps voices sounding human.
- Low similarity: More creative, expressive, and flexible. Great for fictional characters or varied narration.
Tips for using Similarity:
- Use high similarity when you want brand consistency (e.g., a company voice).
- Medium similarity is ideal for everyday narration or conversational styles.
- Low similarity is best for character voices or comedic tones where exaggeration is acceptable.
Trade-off:
High similarity can limit emotional variation — consider combining medium similarity with style exaggeration for natural emotion.
Example:
- High similarity: Brand voice reading an explainer video script
- Low similarity: AI character reading a fantasy dialogue with personality quirks
2.4 Style Exaggeration
What it controls:
Style exaggeration adds emotional emphasis to the voice.
How it affects your audio:
- Low style: Neutral, professional, informational tone. Ideal for tutorials or corporate content.
- Medium style: Conversational, friendly, slightly emotional, perfect for YouTube narration, podcasts, or casual videos.
- High style: Dramatic, expressive, storytelling voice — ideal for character voices, fiction, or emotional narration.
Tips for using Style Exaggeration:
- Test in small increments; overdoing style exaggeration can make the voice sound unnatural.
- Combine with stability adjustments to balance expressiveness and consistency.
- For multi-character scripts, varying style exaggeration can help differentiate personalities.
Example:
- Low: “Here’s how to install the software step by step.”
- Medium: “Hey everyone, welcome back to the channel!”
- High: “The wind howled through the mountains as the hero prepared for battle!”
2.5 Language Override
What it controls:
Language override forces the voice to read in a specific language, even if the text is in another language.
Use cases:
- Multilingual content creation
- Dubbing or translation
- Adding accented or non-native speech for characters
Tips for using Language Override:
- Double-check pronunciation, as forcing a language can slightly alter clarity.
- Combine with medium style and stability to maintain natural flow.
- Use it when you want consistent voice across multiple languages.
Example:
English text + Spanish override → AI reads Spanish translation of your script while keeping the same voice.
2.6 Speaker Boost
What it controls:
Speaker boost enhances loudness, vocal presence, and clarity.
How it affects your audio:
- On: Voice sounds stronger, more present, and podcast-ready. Good for tutorials, ads, or YouTube narration.
- Off: Softer, cinematic, or more natural tone — ideal for audiobooks or emotional storytelling.
Tips for using Speaker Boost:
- Don’t rely solely on speaker boost for audio quality — post-processing in editing software may still be needed.
- On works best for content with background noise or music; off works better for immersive storytelling.
- Adjust in small increments to avoid over-driving the audio.
Example:
- On: “Here’s the step-by-step guide to mastering AI tools!”
- Off: “She whispered the secret to him, afraid of being overheard…”
2.7 How These Settings Work Together
No single setting works alone. Great voice output comes from balancing them.
- Stability + Style Exaggeration:
High stability + low style = professional narration
Low stability + high style = expressive storytelling - Speed + Emotion:
Slower speed increases emotional impact.
Faster speed increases energy and urgency. - Similarity + Expression:
High similarity = accurate voice matching.
Lower similarity = more expressive freedom.
Understanding these interactions is what separates average AI voices from professional-sounding ones.
3. Recommended ElevenLabs Settings by Use Case
Below are proven settings for the most common content types.
3.1 YouTube Faceless Videos
Goal: Clear, consistent, professional narration.
Recommended settings:
- Speed: 1.0–1.15
- Stability: 70–85
- Similarity: 50–70
- Style Exaggeration: 0–20
- Language Override: Off
- Speaker Boost: On
Why this works:
High stability ensures consistent delivery across long videos, while speaker boost gives a strong, polished sound.
3.2 Audiobooks
Goal: Smooth, fatigue-free long listening experience.
Recommended settings:
- Speed: 0.85–1.0
- Stability: 55–75
- Similarity: 60–80
- Style Exaggeration: 0–15
- Language Override: Off
- Speaker Boost: Optional (On for stronger narration, Off for softer tone)
Why this works:
Slower speed and moderate stability make the narration comfortable for long sessions.
3.3 TikTok / Reels
Goal: Fast, energetic, attention-grabbing voice.
Recommended settings:
- Speed: 1.2–1.4
- Stability: 45–65
- Similarity: 40–60
- Style Exaggeration: 40–70
- Language Override: Off
- Speaker Boost: On
Why this works:
Short-form content needs fast pacing and expressive delivery to stop the scroll.
3.4 AI Characters (Gaming, Animation, Storytelling)
Goal: Expressive, personality-rich voices.
Recommended settings:
- Speed: 0.9–1.2 (adjust per character)
- Stability: 20–50
- Similarity: 40–70
- Style Exaggeration: 60–100
- Language Override: Optional
- Speaker Boost: Optional
Why this works:
Low stability and high style exaggeration create dynamic, emotional character voices.
3.5 Deep Emotional Narration
Goal: Dramatic, emotionally impactful storytelling.
Recommended settings:
- Speed: 0.8–1.0
- Stability: 20–45
- Similarity: 50–70
- Style Exaggeration: 70–100
- Language Override: Off
- Speaker Boost: Off or Low
Why this works:
Lower stability and high style exaggeration amplify emotional expression.
3.6 Ultra-Natural Conversational Voices
Goal: Human-like, casual, realistic speech.
Recommended settings:
- Speed: 0.95–1.1
- Stability: 45–65
- Similarity: 50–70
- Style Exaggeration: 20–40
- Language Override: Off
- Speaker Boost: Optional
Why this works:
Balanced settings create a natural, friendly, everyday speaking tone.
3.7 Corporate Training & E-Learning
Goal: Clear, professional, easy-to-follow instruction.
Recommended settings:
- Speed: 1.0–1.1
- Stability: 75–90
- Similarity: 60–80
- Style Exaggeration: 0–15
- Language Override: Off
- Speaker Boost: On
Why this works:
High stability ensures consistency across long training modules and instructional videos.
3.8 News Reading / Documentary Narration
Goal: Neutral, authoritative, trustworthy tone.
Recommended settings:
- Speed: 1.0–1.1
- Stability: 80–95
- Similarity: 60–80
- Style Exaggeration: 0–10
- Language Override: Off
- Speaker Boost: On
Why this works:
Very high stability creates a calm, professional news-anchor-style delivery.
3.9 Marketing Ads & Sales Videos
Goal: Persuasive, energetic, conversion-focused voice.
Recommended settings:
- Speed: 1.1–1.3
- Stability: 40–60
- Similarity: 40–60
- Style Exaggeration: 40–70
- Language Override: Optional
- Speaker Boost: On
Why this works:
Higher style exaggeration and moderate stability create a confident, energetic, sales-driven tone.
3.10 Educational Explainers & Tutorials
Goal: Clear, calm, easy-to-understand delivery.
Recommended settings:
- Speed: 1.0–1.15
- Stability: 65–80
- Similarity: 55–75
- Style Exaggeration: 10–25
- Language Override: Off
- Speaker Boost: On
Why this works:
Medium stability and light style exaggeration maintain clarity while keeping the voice engaging.
3.11 Podcasts & Voiceover Commentary
Goal: Warm, engaging, professional host-style voice.
Recommended settings:
- Speed: 0.95–1.1
- Stability: 55–70
- Similarity: 50–70
- Style Exaggeration: 20–40
- Language Override: Off
- Speaker Boost: On
Why this works:
Balanced stability and style exaggeration create a friendly, natural podcast tone.
3.12 Multilingual Content & Dubbing
Goal: Natural-sounding voice across multiple languages.
Recommended settings:
- Speed: 0.95–1.1
- Stability: 60–80
- Similarity: 60–85
- Style Exaggeration: 10–30
- Language Override: On (as needed)
- Speaker Boost: Optional
Why this works:
Medium-to-high similarity preserves voice identity across languages while maintaining clarity.
| Content Type | Speed | Stability | Similarity | Style | Speaker Boost |
|---|---|---|---|---|---|
| YouTube Faceless | 1.0–1.15 | 70–85 | 50–70 | 0–20 | On |
| Audiobooks | 0.85–1.0 | 55–75 | 60–80 | 0–15 | Optional |
| TikTok / Reels | 1.2–1.4 | 45–65 | 40–60 | 40–70 | On |
| AI Characters | 0.9–1.2 | 20–50 | 40–70 | 60–100 | Optional |
| Emotional Narration | 0.8–1.0 | 20–45 | 50–70 | 70–100 | Off/Low |
| Conversational AI | 0.95–1.1 | 45–65 | 50–70 | 20–40 | Optional |
| Corporate Training | 1.0–1.1 | 75–90 | 60–80 | 0–15 | On |
| News / Documentary | 1.0–1.1 | 80–95 | 60–80 | 0–10 | On |
| Marketing / Ads | 1.1–1.3 | 40–60 | 40–60 | 40–70 | On |
| Educational Tutorials | 1.0–1.15 | 65–80 | 55–75 | 10–25 | On |
| Podcasts | 0.95–1.1 | 55–70 | 50–70 | 20–40 | On |
| Multilingual / Dubbing | 0.95–1.1 | 60–80 | 60–85 | 10–30 | Optional |
4. Common Mistakes to Avoid
Many creators assume that higher emotion always means better voice quality, but this is often not the case. One of the most common mistakes is using high style exaggeration for professional, corporate, or educational content. This can make the voice sound theatrical, salesy, or even cartoonish, which reduces trust and credibility. For business, tutorials, news, and training material, clarity and consistency always matter more than emotion.
Another frequent error is setting stability too low for long-form content. While low stability adds emotion and variation, it also introduces unpredictability in tone and delivery. Over long durations, this inconsistency can cause listener fatigue and reduce comprehension. Long-form narration benefits far more from medium to high stability, even if you later add emotion through scriptwriting rather than voice modulation.
Overusing speaker boost is another pitfall. While it can make voices sound more powerful, excessive boost may introduce harshness, clipping, or unnatural compression — especially if you apply additional audio processing later. Speaker boost should enhance clarity, not overpower the listener or distort the voice.
Creators also commonly ignore speed adjustments, using the same pacing across all content types. Emotional scenes, storytelling, and dramatic narration require slower pacing to allow pauses and emotional impact, while ads and short-form content need faster delivery to maintain attention. Using one speed setting for everything leads to flat, rushed, or disengaging output.
Forcing language override unnecessarily can cause unnatural pronunciation, awkward rhythm, or accent inconsistencies. Language override should only be used when creating multilingual content, dubbing, or intentionally accented voices. Otherwise, letting the model naturally interpret the language usually produces better results.
Finally, many users generate only a short preview and assume the voice will behave the same across longer passages. In reality, voice behavior can change across paragraphs. Always test your voice settings on a longer section of your script before finalizing.
Key mistakes to avoid
- Using high style exaggeration for professional, corporate, or educational content
- Setting stability too low for long-form narration like audiobooks or courses
- Overusing speaker boost, leading to harsh or distorted audio
- Keeping the same speed across emotional, instructional, and promotional content
- Forcing language override when it’s not needed
- Failing to test voice output across longer script sections
5. Advanced Tips for Better Voice Output
High-quality AI voice output doesn’t come from settings alone — it comes from how you write and structure your script. Punctuation, formatting, and spacing directly influence pacing, tone, and emotional delivery. Strategic use of commas, ellipses, line breaks, and short sentences helps guide natural pauses and breathing, making the voice sound more human.
Breaking long scripts into smaller chunks improves both quality and control. Smaller segments reduce generation errors, maintain consistent tone, and make it easier to adjust pacing and emotion for specific sections. This is especially important for audiobooks, courses, and long-form YouTube videos.
Creating reusable voice presets for different content types saves time and ensures consistency across projects. Instead of adjusting settings from scratch every time, store presets for tutorials, ads, storytelling, podcasts, and conversational content.
Testing multiple variations of the same script is one of the fastest ways to improve output. Small changes in stability, style exaggeration, or speed can produce dramatically different results. Generating two or three versions lets you choose the most natural or emotionally appropriate delivery.
Post-processing also plays a critical role. Even the best AI voice benefits from light audio editing — noise reduction, equalization, compression, and volume normalization — to achieve a studio-quality finish.
Embedding emotional cues inside your script, such as “(softly)”, “(excited)”, “(pause)”, or “(whisper)”, can subtly guide delivery and improve emotional accuracy, especially for storytelling and character voices.
Consistency matters. Once you find a voice style that works for your brand or channel, reuse it across all content to build audience familiarity and trust.
Advanced best practices:
- Use punctuation and line breaks to control pacing and emotion
- Break long scripts into smaller sections for better consistency
- Create reusable presets for different content types
- Test 2–3 voice variations before finalizing output
- Apply light post-processing for professional sound quality
- Add emotional cues directly into scripts to guide delivery
- Maintain consistent voice styles across your content library
6. ElevenLabs vs Other Voice AI Tools
While many AI voice tools exist, ElevenLabs consistently stands out in voice realism, emotional depth, and performance control. Compared to platforms like PlayHT, Murf AI, LOVO AI, and Amazon Polly, ElevenLabs produces more natural intonation, smoother pacing, and fewer robotic artifacts, especially in long-form narration.
ElevenLabs excels at emotional expression, allowing voices to convey subtle emotions like warmth, sadness, excitement, tension, and empathy more convincingly than most alternatives. This makes it particularly powerful for storytelling, audiobooks, character voices, and emotionally driven content.
Its voice cloning quality is also among the best in the industry, enabling creators to maintain consistent branded voices or replicate real speakers with high accuracy and natural tone. This is especially valuable for brand identity, podcasts, and multi-episode content.
Another major advantage is the fine-grained control it offers through settings like stability, similarity, style exaggeration, speed, and speaker boost. Many competing tools provide limited customization, whereas ElevenLabs allows creators to fine-tune voices with precision.
While some tools may offer lower pricing, faster generation, or stronger enterprise integrations, ElevenLabs remains the top choice for creators who prioritize voice quality, emotional realism, and creative control over basic text-to-speech output.
Why ElevenLabs stands out
- More natural voice realism with fewer robotic artifacts
- Superior emotional expression and tonal nuance
- High-quality voice cloning and identity preservation
- Fine-grained control over voice performance
- Better consistency across long-form content
- Ideal for creators focused on realism, emotion, and professional-quality audio
7. Alternatives to ElevenLabs: Other Voice AI Tools Worth Considering
While ElevenLabs is one of the most powerful and flexible AI voice platforms available, there are several excellent alternatives worth exploring depending on your needs, budget, and workflow. Below is a curated list of voice AI tools, what they’re best at, and how they differ from ElevenLabs.
1. Play.ht
Play.ht offers a wide library of AI voices and supports many languages. It’s known for ease of use, affordable pricing tiers, and tools optimized for podcast creators and bloggers.
- Best for: Podcasts, audiobooks, educational content
- Strengths: Large voice catalog, multi-language support, simple pricing
- Limitations vs ElevenLabs: Less depth in emotional expression and voice cloning fidelity
2. Murf AI
Murf is a comprehensive voiceover platform with built-in audio editing tools, background music, and collaboration features. Its visual storyboard makes it ideal for teams.
- Best for: Video creators, teams, marketing agencies
- Strengths: Built-in editing, background music, team workflows
- Limitations vs ElevenLabs: Voice realism is good but not as nuanced in emotional delivery
3. LOVO AI
LOVO provides a balance of quality voices and creative customization with an emphasis on storytelling and character voices. It’s often used for advertising and promotional content.
- Best for: Short videos, advertisements, character narration
- Strengths: Creative voice variations, expressive styles
- Limitations vs ElevenLabs: Short-form focus rather than long-form consistency
4. Amazon Polly (AWS)
Amazon Polly is an enterprise-grade text-to-speech service with strong language and regional accent support. It integrates tightly with AWS tools and development workflows.
- Best for: Enterprise applications, custom app voice features
- Strengths: Scalability, global language options, enterprise infrastructure
- Limitations vs ElevenLabs: Less natural emotion and fewer expressive options out of the box
5. Google Cloud Text-to-Speech
Google’s TTS service uses advanced neural voices with strong multi-language support and integrates within the Google Cloud ecosystem.
- Best for: Developers, apps, multilingual systems
- Strengths: Comprehensive language coverage, accurate pronunciation
- Limitations vs ElevenLabs: Standard voices sound more robotic; fewer expressive controls
6. Microsoft Azure Speech Service
Microsoft offers AI voices through Azure, with support for custom voice models and strong developer tools.
- Best for: Enterprise, SaaS voice features
- Strengths: Custom models, reliable scaling, enterprise compliance
- Limitations vs ElevenLabs: Less natural human-like delivery; primarily developer-focused
7. Descript Overdub
Descript’s Overdub tool lets you create a clone of your own voice for instant voiceovers. It’s part of a powerful editing suite, so you can edit audio the same way you edit text.
- Best for: Content creators who want to clone their own voice
- Strengths: Seamless editing workflow, self-voice cloning
- Limitations vs ElevenLabs: Voice realism depends heavily on input samples
8. Speechify
Speechify focuses on reading long text content — like articles, books, or documents — with simple controls and mobile accessibility.
- Best for: Personal reading, accessibility, long-form content
- Strengths: Easy to use, wide device support
- Limitations vs ElevenLabs: Less customization and professional voice options
9. iSpeech
iSpeech specializes in simple, fast text-to-speech conversions with support for apps, media, and embedded voice features.
- Best for: Embedded voice applications, apps, and utilities
- Strengths: Fast generation, API access
- Limitations vs ElevenLabs: Less nuance and fewer high-quality expressive voices
10. Resemble AI
Resemble AI is a strong competitor focused on voice cloning and expressive emotional voices. It allows dynamic control over voice parameters and custom voice creation.
- Best for: Voice cloning, interactive media, character voices
- Strengths: Custom cloning, expressive control, real-time options
- Limitations vs ElevenLabs: Slightly steeper learning curve for beginners
🧠 How to Choose the Right Tool
The best voice AI platform depends on your goals, audience, and workflow:
- Need realistic emotional narration? ElevenLabs, Resemble AI, LOVO
- Team collaboration + editing tools? Murf AI, Descript
- Enterprise or scale focus? Amazon Polly, Azure Speech
- Multilingual & app integration? Google Cloud TTS, Polly
- Personal voice cloning? Descript Overdub, Resemble AI
8. FAQs
Q1. What is ElevenLabs used for?
A1. ElevenLabs is an AI voice generation platform used to create natural-sounding speech for videos, audiobooks, podcasts, ads, games, and more.
Q2. How does stability affect voice output?
A2. Stability controls how consistent or expressive the voice is — higher stability sounds steady and professional, while lower stability adds emotion and variation.
Q3. Can I clone my own voice with ElevenLabs?
A3. Yes, ElevenLabs allows voice cloning using recorded samples to create a digital version of your voice.
Q4. What is style exaggeration in ElevenLabs?
A4. Style exaggeration controls how dramatic or emotionally expressive the voice sounds.
Q5. Is ElevenLabs suitable for audiobooks?
A5. Yes, it’s one of the best tools for audiobooks due to its natural pacing, emotional range, and long-form consistency.
Q6. What happens if similarity is set too high?
A6. Very high similarity can reduce emotional flexibility, making the voice sound accurate but less expressive.
Q7. Can ElevenLabs generate multilingual voices?
A7. Yes, it supports multiple languages and can generate voices across different accents and regions.
Q8. What does speaker boost do?
A8. Speaker boost increases vocal presence, clarity, and loudness, making voices sound more podcast-ready.
Q9. Is ElevenLabs better than Amazon Polly?
A9. ElevenLabs generally offers more natural and emotionally expressive voices, while Polly excels in enterprise scalability.
Q10. What speed setting is best for storytelling?
A10. A slower speed (around 0.8–1.0) works best for emotional and narrative content.
Q11. Can ElevenLabs be used for real-time voice generation?
A11. Some plans and integrations support near real-time voice synthesis for interactive applications.
Q12. What’s the difference between stability and style exaggeration?
A12. Stability affects consistency, while style exaggeration affects emotional intensity and dramatic delivery.
Q13. Is ElevenLabs suitable for YouTube faceless channels?
A13. Yes, it’s ideal due to its professional tone, natural delivery, and consistent voice quality.
Q14. How do I make voices sound more human-like?
A14. Use medium stability, moderate style exaggeration, proper punctuation, and natural script structure.
Q15. Can I use ElevenLabs for commercial projects?
A15. Yes, depending on your plan, ElevenLabs offers commercial usage rights.
Q16. What is language override used for?
A16. Language override forces the voice to speak in a specific language, regardless of the input text language.
Q17. Does ElevenLabs work for emotional scenes?
A17. Yes, it excels at emotional narration when using low stability and high style exaggeration.
Q18. Can ElevenLabs replace human voice actors?
A18. It can replace voice actors for many use cases, but human actors are still preferred for highly nuanced performances.
Q19. How accurate is ElevenLabs voice cloning?
A19. It offers industry-leading voice cloning accuracy with high similarity and natural tone.
Q20. Can I use ElevenLabs for TikTok or Reels?
A20. Yes, faster speed and higher style exaggeration make it perfect for short-form content.
Q21. What causes robotic-sounding output?
A21. Very high stability, low style exaggeration, poor punctuation, or overly formal scripts can make voices sound robotic.
Q22. How do I improve long-form narration quality?
A22. Use moderate stability, slower speed, break scripts into chunks, and apply light post-processing.
Q23. Can ElevenLabs handle multiple speakers in one project?
A23. Yes, you can use different voices for different characters or segments.
Q24. What are the best settings for conversational voices?
A24. Speed 0.95–1.1, stability 45–65, style exaggeration 20–40, speaker boost optional.
Q25. Is ElevenLabs better than Murf AI?
A25. ElevenLabs offers more realistic emotional voices, while Murf excels in team workflows and built-in editing.
Q26. Does ElevenLabs support accents?
A26. Yes, it supports various accents and regional voice styles.
Q27. How do I avoid harsh audio output?
A27. Avoid overusing speaker boost and apply soft compression and EQ during post-processing.
Q28. Can ElevenLabs be used for character voices in games?
A28. Yes, it’s widely used for game characters due to expressive control and voice variation.
Q29. What is the ideal similarity setting for branded voices?
A29. A similarity range of 60–80 works best for consistent branded voices.
Q30. Can I automate voice generation using APIs?
A30. Yes, ElevenLabs provides APIs for automated voice generation and app integration.
Q31. How does punctuation affect voice output?
A31. Punctuation controls pauses, rhythm, and emotional flow, significantly improving realism.
Q32. Is ElevenLabs suitable for corporate training videos?
A32. Yes, high stability and low style exaggeration produce professional, instructional tones.
Q33. Can I combine ElevenLabs voices with background music?
A33. Yes, combining voices with music enhances engagement, especially in videos and podcasts.
Q34. What’s the best way to test voice settings?
A34. Generate 2–3 versions with slight variations and choose the most natural-sounding output.
Q35. Does ElevenLabs support children’s voices?
A35. Yes, it offers voice options suitable for children’s content and educational material.
Q36. How do I make voices sound more cinematic?
A36. Use lower stability, higher style exaggeration, slower speed, and softer speaker boost or none.
Q37. Can ElevenLabs be used for dubbing videos?
A37. Yes, it’s commonly used for multilingual dubbing with language override and timing adjustments.
Q38. What’s the best setting for ads and marketing videos?
A38. Speed 1.1–1.3, stability 50–70, style exaggeration 40–60, speaker boost on.
Q39. Does ElevenLabs work well for accessibility content?
A39. Yes, it’s excellent for accessibility, screen readers, and educational narration.
Q40. How do I maintain consistent voice quality across projects?
A40. Create reusable presets, standardize your script style, and reuse the same voice profiles.





